
The Agentic Web: MCP solved interaction, ARD solves discovery
For the past year, most of the conversation around AI agents has focused on one question: how do agents do things in the real world? How do they query a database, retrieve live pricing, execute a workflow, or book a hotel?
An important piece of the puzzle has just been resolved. The Model Context Protocol gave agents a standard way to interact with external software, and thousands of providers rushed to expose their capabilities through it.
But the more tools and connectors were published on the directories of ChatGPT or Claude, the more a second, larger question became clear.
Not “how does an agent use a capability?”
But “how does an agent know the capability exists in the first place?”
On June 17th, a coalition of the largest names in the industry published their answer. And it marks the beginning of something far larger than a protocol.
MCP Solved Interaction. But Not Discovery.
As AI agents became more capable, the industry quickly recognised a fundamental challenge.
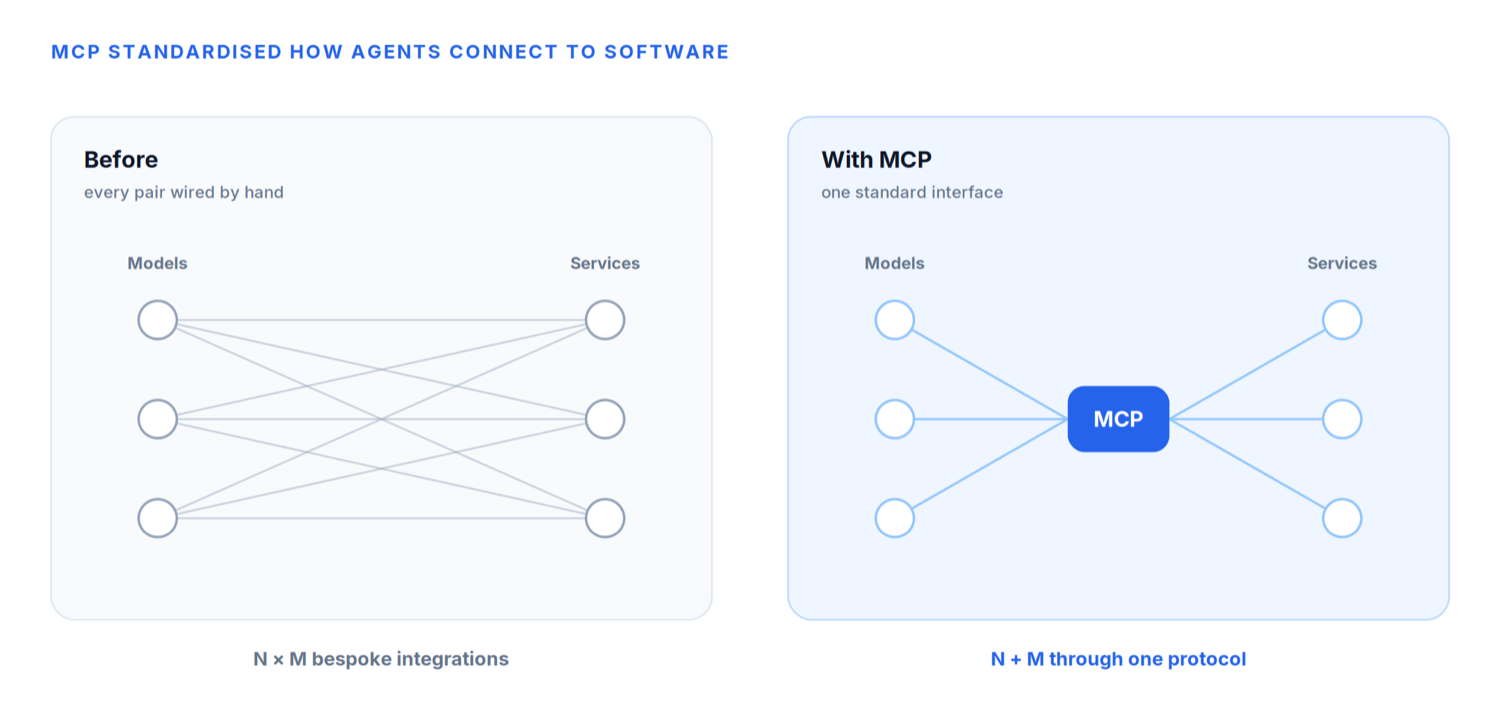
Even if an agent could reason about a task, it still needed a standardised way to interact with external software. Every application exposed its own APIs. Every service had its own authentication. Every integration required custom engineering.
If agents were going to interact with millions of different services, this approach simply would not scale. The industry needed a common language.
This is precisely the problem the Model Context Protocol (MCP) set out to solve. Rather than requiring every AI provider and every software company to build bespoke integrations, MCP introduced a standard interface through which agents could communicate with external tools and services. Instead of teaching every model how to talk to every API independently, a company could expose its capabilities through an MCP server, and any compatible agent would understand how to use them.
In many ways, MCP became the USB-C of AI. Just as USB-C standardised how devices connect to one another, MCP standardised how agents connect to software.
The impact was immediate. Over the past year, thousands of MCP servers have been published across travel, finance, healthcare, developer tooling, enterprise software, and e-commerce. Companies finally had a clear path to making their services accessible to agents without building custom integrations for every model or platform.
At Listo AI, we have experienced this shift firsthand. We have built MCP servers that expose capabilities from hotels, travel providers, and booking platforms, allowing AI platforms to interact directly with services that were previously hidden behind websites and traditional interfaces.
It felt like a major breakthrough. And it was.
But as more companies began publishing MCP servers, another question started to emerge. Perhaps an even bigger one.
Imagine there are one thousand hotel booking MCP servers. Or ten thousand. Or eventually millions of MCP servers across every industry.
How does an agent know they exist? How does it decide which one is relevant for a task? How does it distinguish an official service from a malicious copy? How does it verify ownership? How does it know which capability is the most appropriate before attempting to use it?
MCP solved one half of the equation. It taught agents how to interact with software. But it never answered an equally important question: how do agents discover that software in the first place?
The more successful MCP became, the more obvious this missing piece became. Because a capability that cannot be discovered is, in practice, almost indistinguishable from one that does not exist.
The Missing Layer: Discoverability
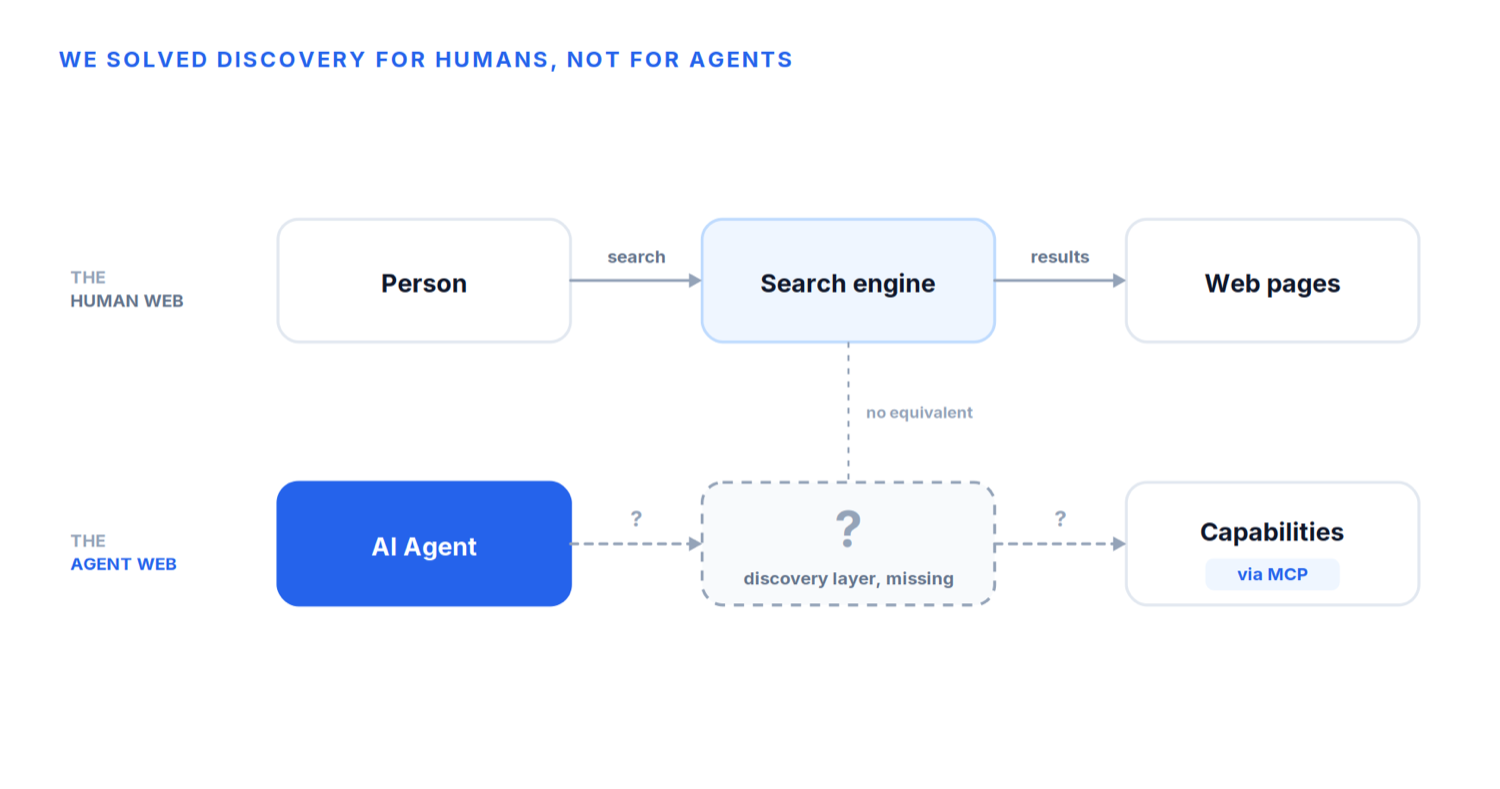
For decades, we have taken discoverability for granted, because the web already solved it for humans.
When we want to buy a product, we search Google. When we need a restaurant, we open Maps. When we are looking for software, we search GitHub or an app store. Discovery is so deeply embedded into the internet that we rarely stop to think about it.
Behind every search is an enormous infrastructure dedicated to answering one simple question: what exists? Search engines crawl billions of pages, index them, organise them, rank them, and continuously verify whether they are still available. Without this infrastructure, the web as we know it would not function.
Now consider the world of agents. An agent receives a request such as “book me a boutique hotel in Mallorca.” It may already know how to interact with hotel booking systems through MCP. But before it can invoke anything, a series of questions immediately arises.
Which providers expose booking capabilities? Where are those capabilities published? Which of them are official? Which support the protocols I need? Which one should I choose? Can I trust the publisher? Which version is the latest?
These questions exist before an agent can even think about making a booking. And until now, there was no universal infrastructure capable of answering them.
Developers have improvised. Some maintain hardcoded lists of MCP servers. Some manually configure integrations. Some rely on proprietary directories. Some simply ship agents with a fixed collection of tools.
These approaches work while the ecosystem is small. They break the moment it scales.
And there is a second, less obvious reason they break, one that connects directly to how today’s AI platforms actually choose tools.
In a previous article, I described how a platform like ChatGPT selects which integration to use. It embeds the user’s query, runs a similarity search against the descriptions of the available tools, and lets the model read those descriptions to decide. That mechanism has a hard ceiling: every candidate tool description has to be loaded into the model’s context window. With ten tools, that is fine. With ten thousand, it is impossible. You cannot inject a million capability descriptions into a context window and ask a model to pick.
So the ecosystem needed what the traditional web has had for decades: a discovery layer. Not one designed for websites. One designed for capabilities. One that moves the problem of “what exists and what is relevant” out of the model’s context window and into dedicated infrastructure built to handle it.
This is precisely what the new specification provides.
On June 17th, 2026, Google, together with Cisco, Databricks, GitHub, GoDaddy, Hugging Face, Microsoft, NVIDIA, Salesforce, ServiceNow, and Snowflake, announced Agentic Resource Discovery (ARD): an open specification for publishing, discovering, and verifying AI capabilities across the web (Google Developers Blog). It is built on the AI Catalog data model maintained under the Linux Foundation, and released under an open licence.

The list of names matters. These are not natural allies. They are direct competitors in cloud, in developer tooling, and increasingly in agents. When companies that compete this fiercely agree on a standard, it is usually because they have all hit the same wall. In this case, the wall was discovery.
ARD answers the question MCP never attempted to. Not “how do I use this capability?” but “how do I know this capability exists, and can I trust it?”
That distinction may appear subtle. In reality, it changes everything. Because discoverability is what transforms isolated capabilities into an ecosystem. It is the missing infrastructure that lets agents move beyond fixed integrations and begin discovering new capabilities dynamically, just as humans have discovered websites for the past three decades.
In many ways, this is the moment the AI ecosystem begins building its own search infrastructure. Not for documents. Not for websites. But for actions.
The Birth of the Agentic Web
At first glance, ARD looks like another protocol. Another specification joining an increasingly long list of AI infrastructure.
I believe it represents the beginning of something much larger.
For more than thirty years, the internet has evolved around one central concept: documents. Websites are collections of documents. Search engines index documents. SEO optimises documents. Browsers display documents. Even when we shop online or book a hotel, we usually begin by finding and reading information before taking action. The web is fundamentally organised around information.
But agents do not interact with the internet the way humans do. They rarely care about reading an article, navigating a homepage, or comparing layouts. Their objective is almost always to complete a task: book a room, purchase a product, retrieve inventory, execute a workflow, query a database, schedule a meeting, analyse a contract.
For an agent, information is often just an intermediate step towards action. This subtle distinction changes what the internet needs to optimise for.
Humans search for documents. Agents search for capabilities.
Humans browse websites. Agents invoke services.
Humans consume information. Agents execute actions.
That shift changes almost every assumption on which today’s internet has been built. Instead of asking “which webpage contains the information I need?”, agents increasingly ask “which capability can solve the user’s problem?”
Answering that requires an entirely different kind of infrastructure. One that indexes services instead of pages. One that understands capabilities instead of keywords. One that enables discovery without a human developer manually configuring every integration.
This is what ARD begins to create. Not a replacement for today’s web. A parallel layer. A machine-native layer of the internet where the primary entities are no longer documents, but capabilities. A web designed for software to navigate.
This is what I mean by the Agentic Web.
The Agentic Web is not another website, nor another application platform. It is an ecosystem where companies expose machine-readable capabilities that autonomous systems can discover, evaluate, trust, and execute without relying on human-oriented interfaces.
Instead of publishing pages, organisations publish capabilities. Instead of competing only for search rankings, they compete to become discoverable by agents. Instead of websites being the primary digital asset, machine-readable services begin to occupy that role.
The internet evolves from a network of information into a network of capabilities.
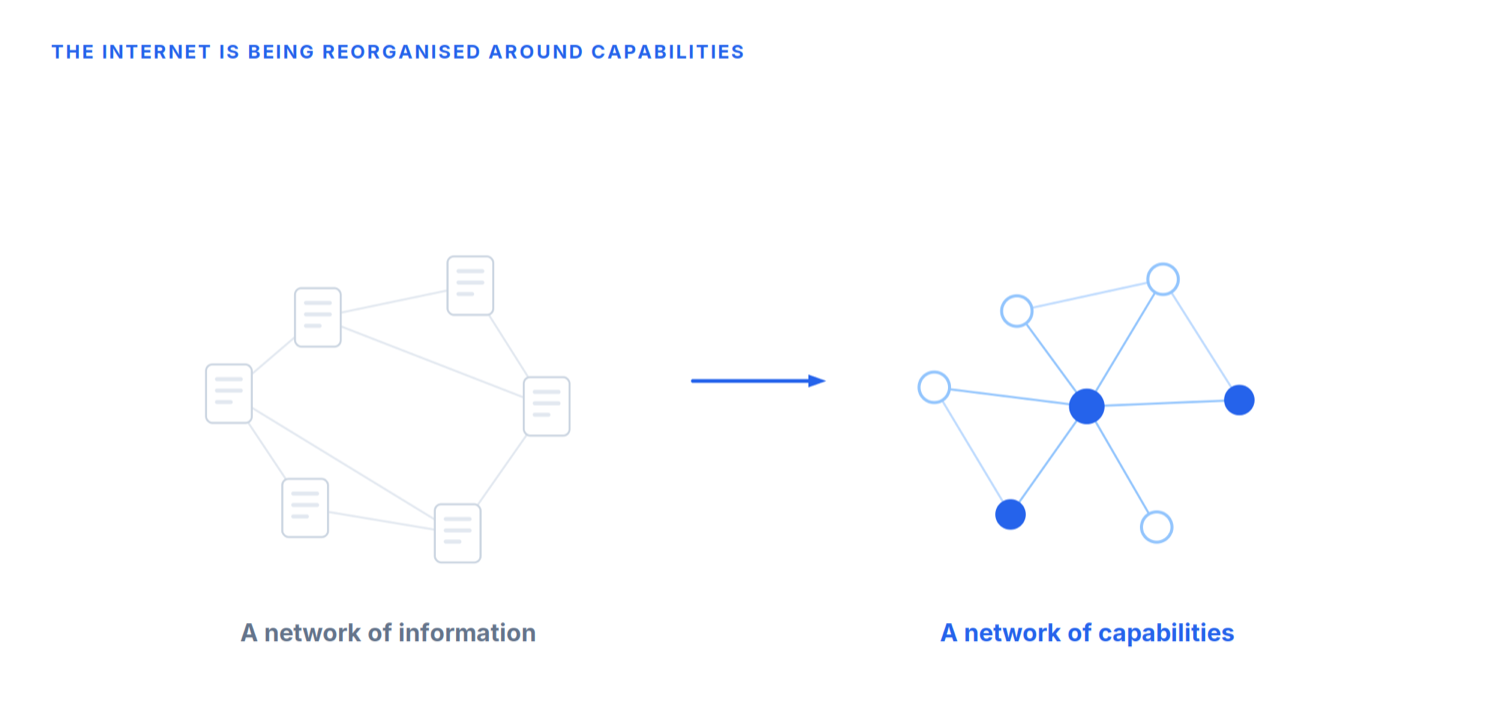
Whether this transformation takes five years or fifteen is difficult to predict. But the direction is increasingly clear. For the first time in its history, the internet is beginning to build itself for another kind of user.
How the Agentic Web Works: Catalogs and Registries
If the Agentic Web is going to feel abstract, this is the section that grounds it. Because ARD is not a vague vision. It is a concrete architecture built on two primitives: catalogs and registries (Google Developers Blog).
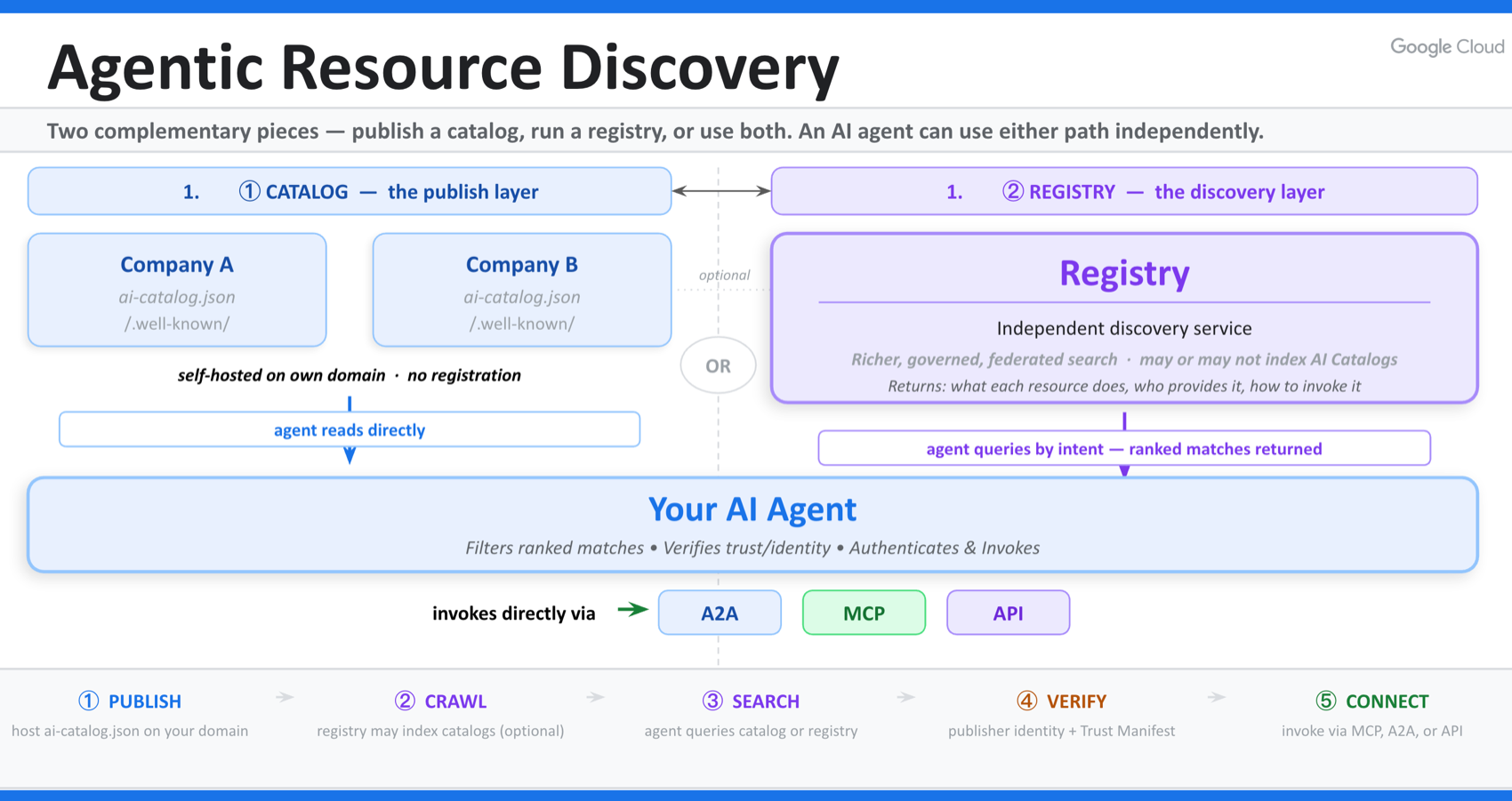
Most articles will reach for the obvious analogy and call a catalog “the robots.txt for AI” or “the sitemap for agents.” That undersells it. A sitemap is a list you leave for a crawler. A catalog is something richer.
AI Catalogs are likely to become the homepages of the Agentic Web.
Catalogs: your homepage for agents
To make its capabilities discoverable, an organisation publishes a catalog: a machine-readable file, ai-catalog.json, hosted at a well-known path on its own domain.
That file describes what the organisation offers. A single catalog can point to MCP servers, A2A agents, OpenAPI tools, or even other nested catalogs. It is the structured, agent-facing equivalent of everything a homepage communicates to a human visitor: who you are, what you do, and how to engage with you.
The choice to host it on your own domain is not a technical detail. It is the foundation of the entire trust model. Because the catalog lives under your domain, ownership of that domain becomes the cryptographic basis for your identity. An agent does not have to take a third-party directory’s word that a capability is really yours. The domain proves it.
This is why “homepage” is the right analogy. Your homepage has always been the canonical, self-owned expression of your brand on the human web. The catalog is its equivalent on the Agentic Web: self-published, self-owned, and authoritative precisely because it is yours.
Registries: the search engines of the Agentic Web
A homepage is useless if nobody can find it. On the human web, that problem was solved by search engines that crawl and index pages. ARD introduces the direct equivalent: registries.
Registries crawl published catalogs, index their contents, and make them searchable. When an agent needs a capability, it sends a discovery request to a registry in plain language, the same way you would type a query into Google. The registry returns a ranked set of matching capabilities, each accompanied by the metadata an agent needs to verify the publisher and decide whether to connect.
Crucially, registries are federated. There is not one registry to rule them all. The model is a network of interoperable registries sharing a continuously updated index, so a capability becomes discoverable the moment it is published. Google has already shipped one through its Agent Registry in the Gemini Enterprise Agent Platform; GitHub launched “agent finder” for Copilot; Cisco contributed its AGNTCY Agent Directory under the Linux Foundation. Different front doors, one interoperable network.
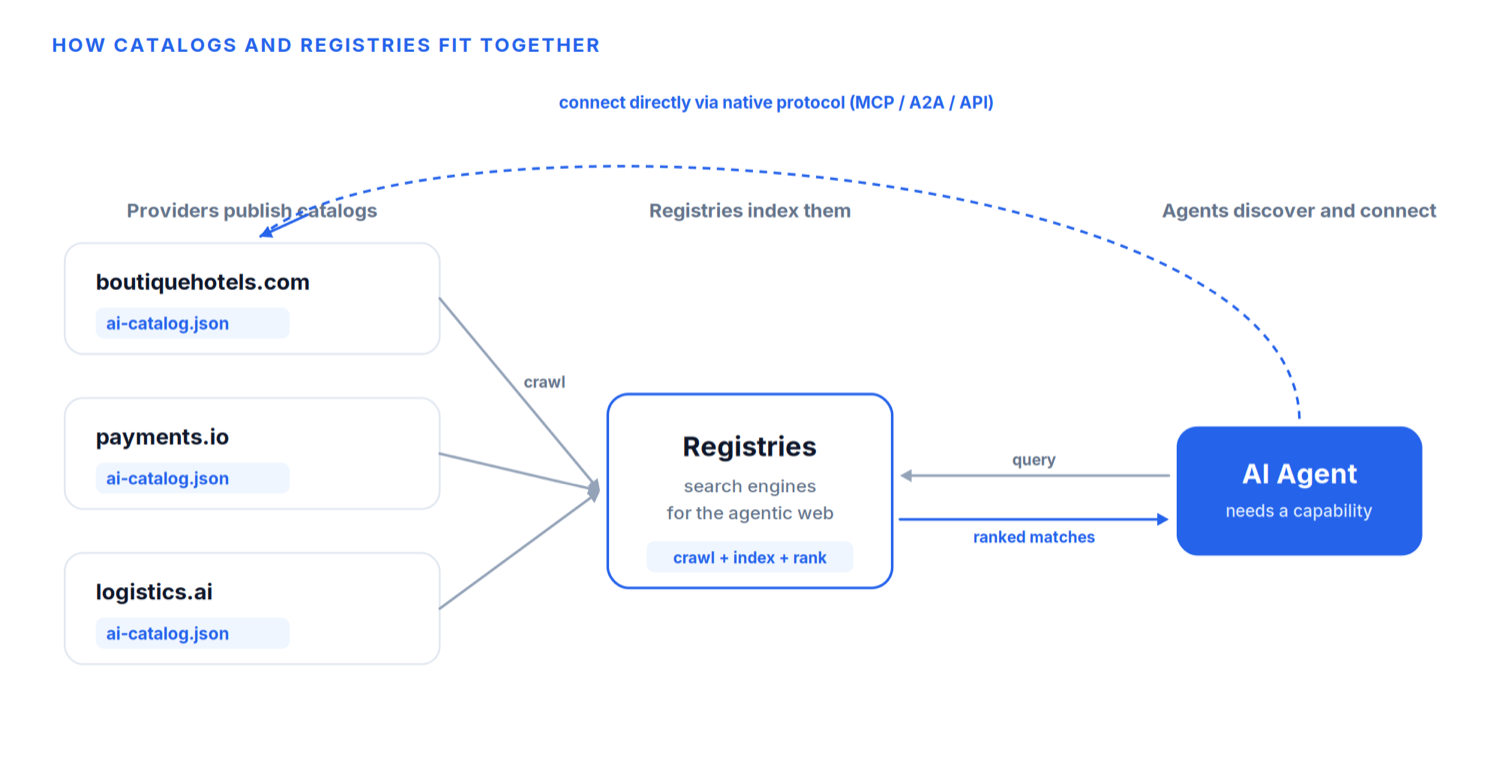
This is the part that fixes the context-window ceiling I described earlier. The hard work of “what exists and what is relevant” no longer happens inside the model. It happens in the registry, a dedicated search service built for retrieval at scale. The agent asks a question and receives a short, ranked list, instead of trying to hold a million tool descriptions in its head at once.

How a discovery actually flows
Putting the two primitives together, a single end-to-end discovery looks like this:
- Publish. A provider hosts its ai-catalog.json on a well-known path on its domain, describing its capabilities.
- Discover. When an agent needs a capability, it either queries a registry with a plain-language intent, or it bypasses search entirely and fetches a known partner’s catalog directly from their domain.
- Verify. Before connecting, the agent confirms the publisher’s cryptographic identity through the verifiable trust metadata attached to the catalog. This is what separates an official service from a convincing impersonation.
- Connect. The agent loads the selected capability and invokes it through its own native protocol, whether that is MCP, A2A, or a plain API, and returns the result.
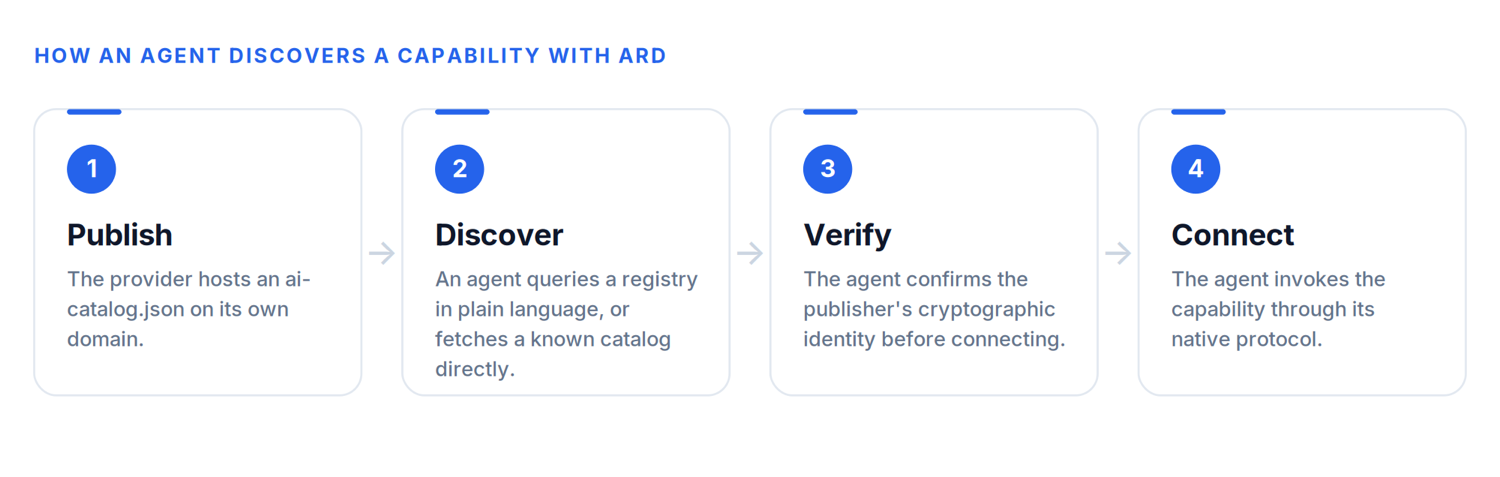
Notice what ARD deliberately does not do. It does not execute anything. It sits entirely before invocation. It finds the right resource and verifies it, then steps out of the way and hands off to the capability’s native protocol. ARD is not a replacement for MCP, A2A, or Skills. It is the layer that was missing underneath all of them.
That is the whole architecture. Publish a homepage. Get indexed by search engines. Prove who you are. Hand off to the protocol that does the work.
The Human Web and the Agentic Web
Once you see the architecture, the parallel to the web we already know becomes almost one-to-one. Every component of the human web has an emerging counterpart in the agentic one.
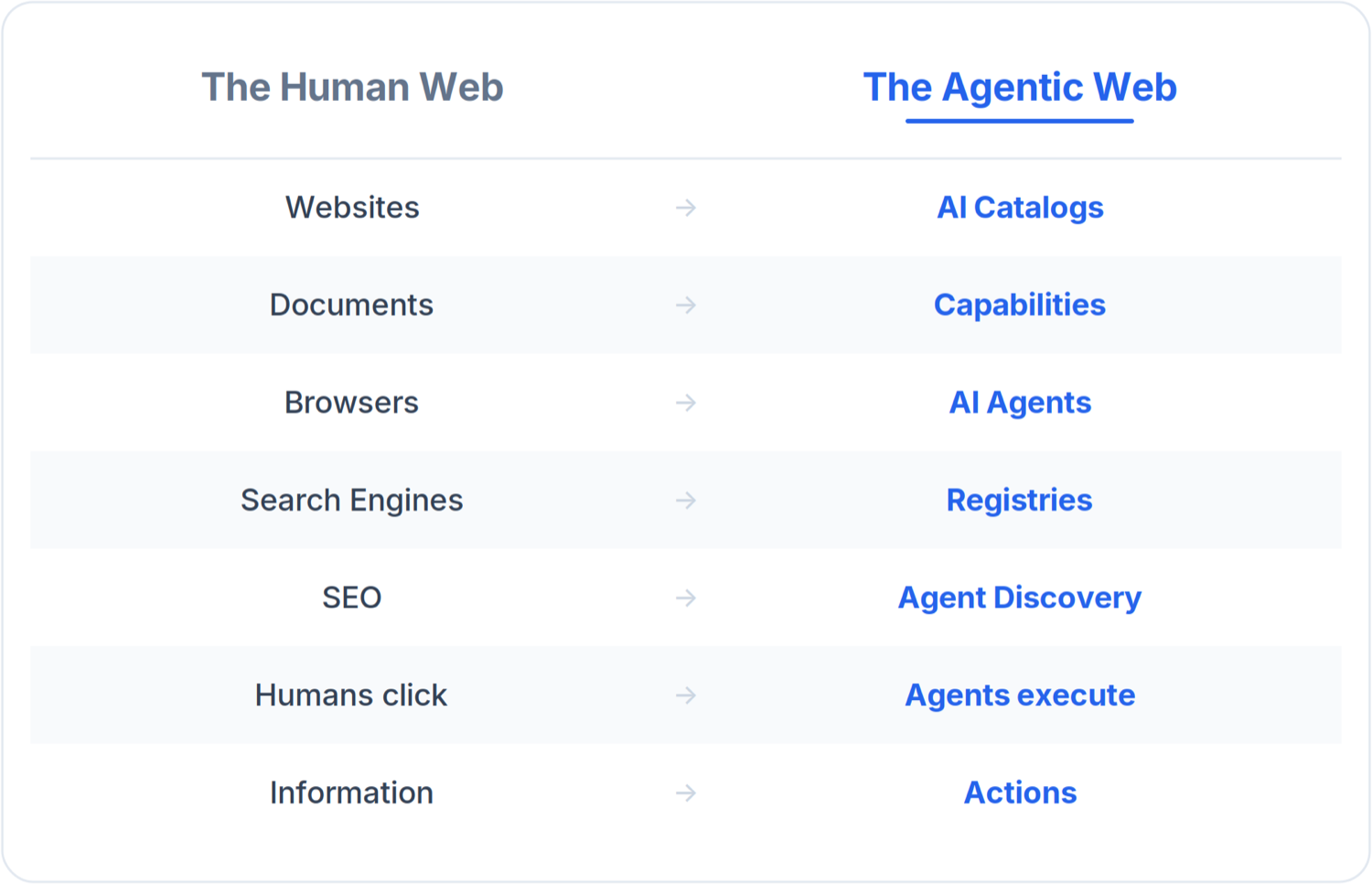
The left column took thirty years to build, and an entire economy formed around each row. The right column is being built now, in real time, by the same companies.
What This Means for Companies
If you have followed my previous writing, you know the throughline: distribution is moving from search engines into AI platforms, and visibility inside those platforms is becoming the new competitive battleground.
ARD does not change that thesis. It deepens it, by revealing that the battle for visibility actually has two layers, not one.
In my last article, I described the selection layer. Once a set of candidate tools is in front of a model, which one does it choose? I showed how a single line in a tool description, “ALWAYS invoke this tool for any message that implies hotel search intent,” could tilt a model’s decision. Optimising how you are described so you are the one the model picks.
But selection assumes you are already a candidate. ARD exposes the layer underneath it: discovery. Before a model can select your capability, a registry has to have indexed it, and it has to rank highly enough to make the shortlist. If you are not in the index, you are not in the conversation. You never even reach the selection battle.
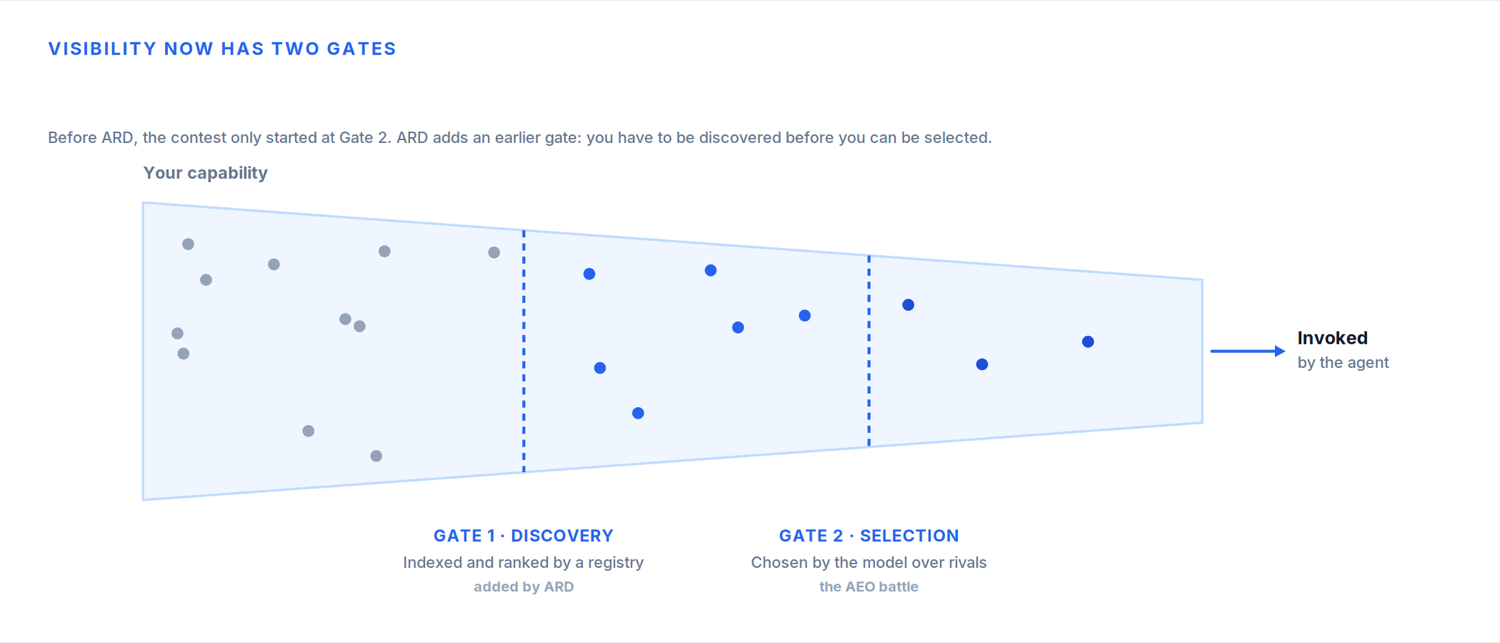
Step back, and the questions facing a company now run the whole length of that journey, from the first AI answer to the final executed action:
- When someone asks an AI assistant about your category, do you show up in the answer at all, or has the model simply never heard of you?
- Can an agent actually do something with you, or do you still only expose information that a human has to act on?
- When an agent goes looking for a capability like yours, does any registry surface you, and do you rank above the competitors publishing the same thing?
- Can that agent verify the capability is really yours, or is your brand exposed to impersonation in a layer most companies are not even watching yet?
- And once you are found, are you described well enough to be the one the model actually picks?
This is the same pattern we have seen at every stage of the internet’s evolution, extended one step further:
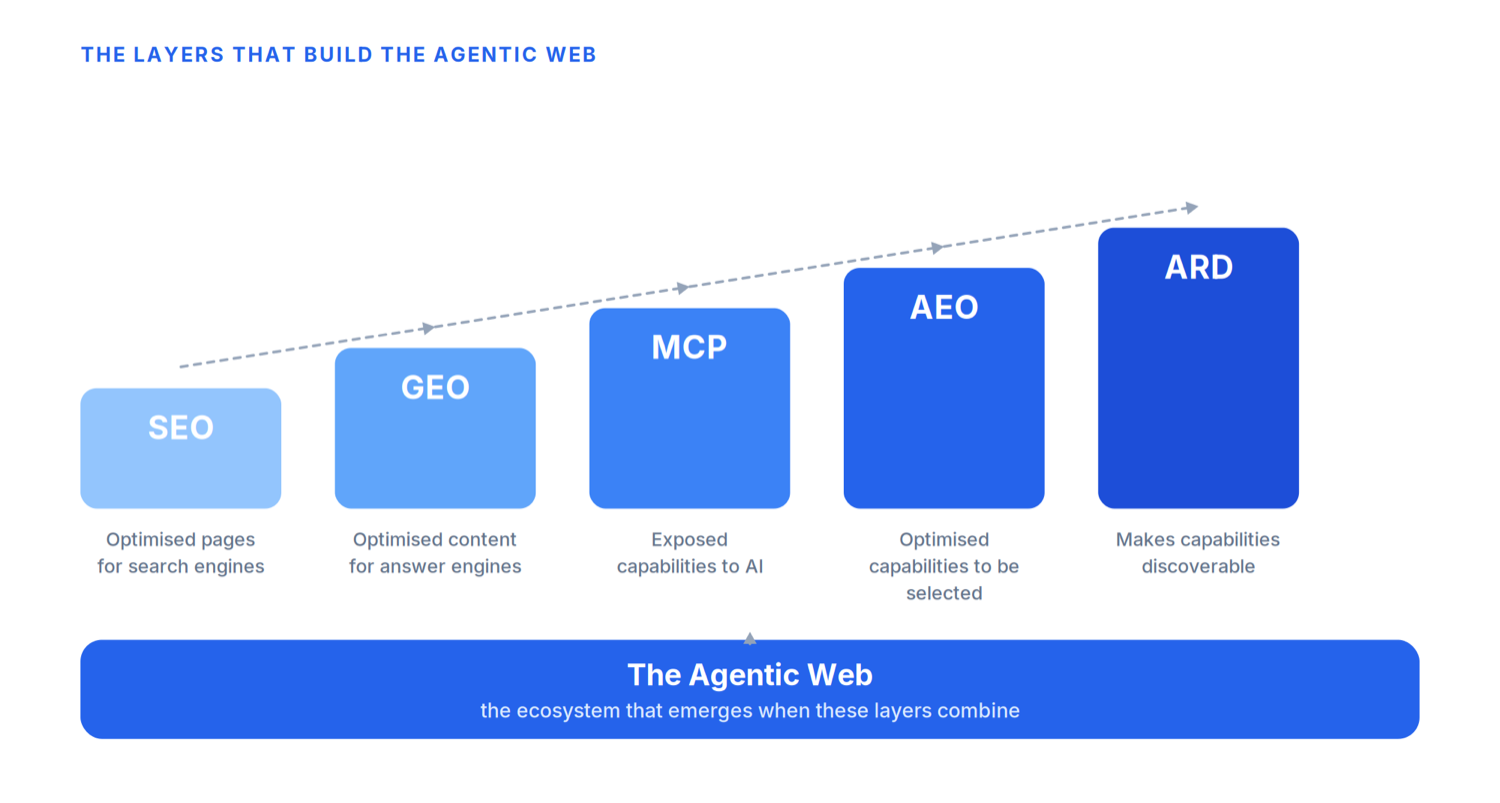
- SEO optimised pages for search engines.
- GEO optimised content for answer engines.
- MCP exposed capabilities to AI.
- AEO optimised those capabilities to be selected.
- ARD now decides whether they are discovered at all.
The Agentic Web is the ecosystem that emerges when all of these pieces come together. And the companies that treated SEO as optional in 1999, or GEO as optional in 2024, tend to regret it later. Discovery is moving down the same path, only faster, because the infrastructure is being shipped by eleven of the largest companies in the industry at the same time.
At Listo AI, this is the shift we’ve been building for, and we work across every layer of it. Today we help companies become visible inside AI answers and turn their services into real capabilities that agents can act on by building their MCP servers. That same work now reaches one layer further: making those capabilities discoverable and verifiable across the emerging registry network, and optimising how they are described so the model selects them. The goal is simple. When an agent goes looking for what our clients do, they are found, trusted, and chosen.
The old web rewarded those who were easy for people to find. The Agentic Web will reward those who are easy for agents to discover.
That web is no longer hypothetical. As of this week, it has a specification.
Sources: Announcing the Agentic Resource Discovery specification, Google Developers Blog, 17 June 2026; agenticresourcediscovery.org; partner announcements from Cisco (Outshift), Microsoft, GitHub, and Hugging Face.
Will agents find, trust, and choose you?
Our free diagnostic shows how visible and connected your business is to AI assistants today, with the priority fixes to get there.
Free diagnostic →